ASR from Scratch III: Training models of Bora, a Low-resource Language (MFA)
This chapter we focus on Bora, an endangered indigenous language of South America, primarily spoken in the western Amazon rainforest. I will demonstrate how to train a mini Bora acoustic model for forced alignment. Even with just 1.5 hours of Bora speech from Dr Jose Elias-Ulloa’s fieldwork, we can produce surprisingly decent time-aligned TextGrids.
This tutorial is designed for researchers working on low-resource languages, where open-source speech materials are scarce and pre-trained models are not available.
For the installation of MFA, please refer to §4.1 in the previous chapter or the official installation guide.
Table of Contents
5.1 The fieldwork dataset
Phonetic fieldwork on a lesser-studied language often begins with recording word lists and short stories.
The Bora data we used here consist of 913 sound files (.wav) with about 1.55 hours total duration from one Bora speaker.
The majority of these files feature a single word repeated three times with pauses in between (see below), while 152 files contain longer utterances drawn from short stories.
In this case, we also have the list of words that the informant read out aloud. For instance, in a text file wordlist.txt, we have:
...
gábuuve
gáyaga
gayága
garága
gapáco
gááraco
gáárapo
gáápaco
gaañúro
...
For longer utterances, each audio file has a transcription roughly marked in a corresponding TextGrid file as follows:

02_sp_Panduro_ROR001_20250212_016.wavThese utterances are ready for training an acoustic model using MFA.
All sound files are organised in a repository bora_corpus/ under the project repository bora/.
Temporarily, we can place all the word list recordings in a separate working directory, words_in_isolation/, to make transcript generation easier.
├── bora
... ├── bora_dict.txt
├── wordlist.txt
├── create_input_tgs_from_wordlists.py
├── create_input_tgs_with_sils.praat
├── words_in_isolation # temporatry
| ├── 01_sp_Panduro_BOR001_20250203_001.wav
| ├── 01_sp_Panduro_BOR001_20250203_002.wav
| └── ...
├── ...
└── bora_corpus
├── 01_sp_Panduro_BOR001_20250203_001.wav
├── 01_sp_Panduro_BOR001_20250203_002.wav
├── 01_sp_Panduro_BOR001_20250203_003.wav
├── ...
└── ... #913 wav items in total
5.2 Data Preprocessing
5.2.1 Transcripts preparation: initial TextGrids in two approaches
The next step is to prepare an input transcription for each wordlist sound file.
I recommend using the .TextGrid format when using MFA (.txt or .lab should work too).
Here I demonstrate two options for the input TextGrids.
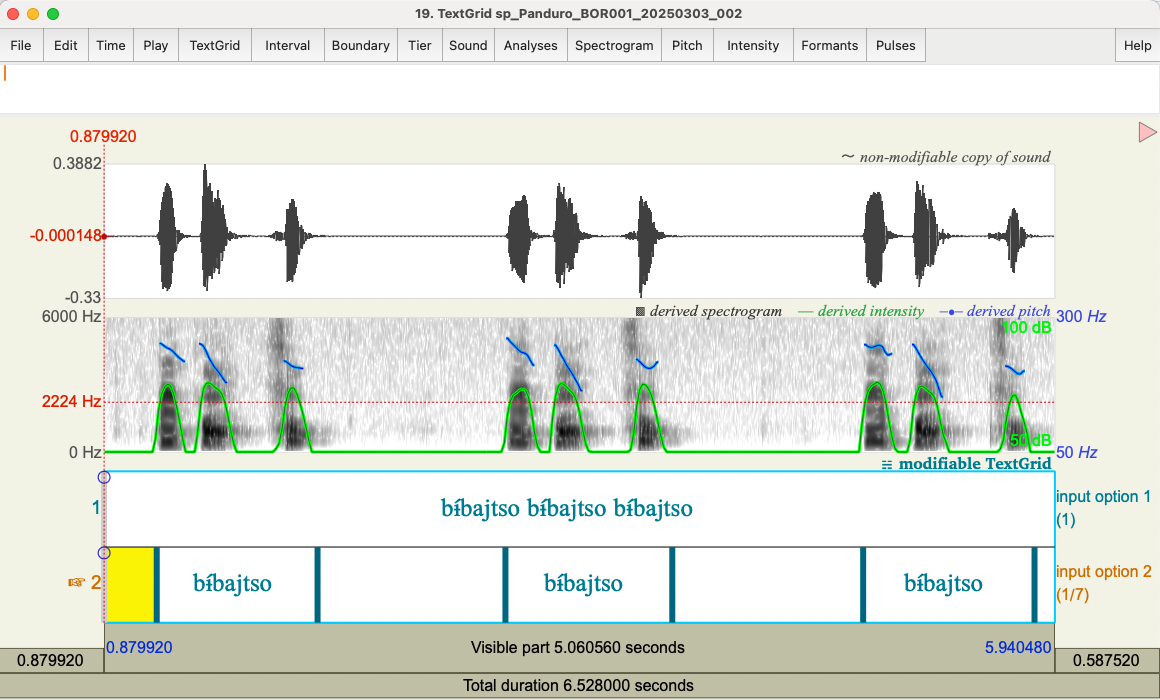
Option ❶ for the word list transcription:
The following Python script create_input_tgs_from_wordlists.py prepares the initial transcript files by
creating a corresponding .TextGrid file for each audio recording,
extracting the corresponding word from the word list, and writing it to a word tier (see above figure, Tier 1).
Note that the audio filenames are neatly ordered and correspond to the order of the word list.
To use this Python script, we can do the following in your unix shell:
cd ~/Wip/bora #your project repository
python create_input_tgs_from_wordlists.py
You will need to pre-install packages such as soundfile and praatio in your environment.
# create_input_tgs_from_wordlists.py
# Created by Chenzi Xu on 31/07/2025
import os
import soundfile as sf
from praatio import textgrid
# Path to the audio folder and dictionary
audio_folder = "words_in_isolation"
dictionary_file = "wordlist.txt"
# Load words from wordlist
with open(dictionary_file, "r", encoding="utf-8") as f:
words = [line.strip().split()[0] for line in f if line.strip()]
# Sort audio files (make sure it's consistent with dictionary order)
audio_files = sorted([f for f in os.listdir(audio_folder) if f.endswith(".wav")])
# Check count matches
if len(audio_files) != len(words):
raise ValueError(f"Mismatch: {len(audio_files)} wav files vs {len(words)} words")
# Loop over each file and create TextGrid
for i, (wav_file, word) in enumerate(zip(audio_files, words)):
wav_path = os.path.join(audio_folder, wav_file)
with sf.SoundFile(wav_path) as f:
duration = len(f) / f.samplerate
label = f"{word} {word} {word}"
tg = textgrid.Textgrid()
tier = textgrid.IntervalTier("word", [(0.0, duration, label)], 0.0, duration)
tg.addTier(tier)
base_name = os.path.splitext(wav_file)[0]
tg_name = f"{base_name}.TextGrid"
tg.save(
os.path.join(audio_folder, tg_name),
format="long_textgrid",
includeBlankSpaces=True,
)
print("Done! TextGrids created for all audio files.")
Option ❷ for the word list transcription: Bootstrapped input TextGrids
The problem with the first approach is that the onset boundaries of words tend to be messy in the output when the dataset is extremely small. One way to address this is to create additional bootstrapped input TextGrids to provide more information (e.g. initial time boundaries) about the speech intervals. We can potentially use the word tier of first-pass output as input and rerun the training and/or alignment.
Or we can use the following Praat script to generate initial word boundaries through silence/speech detection (see above figure, Tier 2). This method works well when the recording of the word lists is highly consistent without much environmental noises (good clean recordings).
In this Praat script, the key parameters we need to consider is in this line:
To TextGrid (silences): 75, 0, -35, 0.15, 0.1, "", word$
- Parameters for the intensity analysis:
- Pitch floor (Hz)
- Time step (s): 0.0 (= auto)
- Silent intervals detection:
- Silence threshold (dB)
- Minimum silent interval (s)
- Minimum sounding interval (s)
- Silent interval label
- Sounding interval label
This command takes seven arguments, among which the pitch floor, silence threshold, and minimum silent interval (in seconds)
typically need to be customized based on the speech data — for example, the speaker’s pitch range and speech rate, the recording conditions, and the level of background noise.
A practical way to determine optimal values is to randomly open a few sound files in Praat
and run the command from the graphical interface (Annotate >To TextGrid (silences)) with a range of parameters
to get a feel for the best parameters.
# create_input_tgs_with_sils.praat
# Written by Chenzi XU (30 July 2025)
form Batch annotate wordlist
sentence WordListFile /Users/chenzi/Wip/bora/wordlist.txt
sentence AudioFolder /Users/chenzi/Wip/bora/words_in_isolation
endform
Read Strings from raw text file... 'WordListFile$'
Rename... wordList
numberOfWords = Get number of strings
Create Strings as file list... wavList 'AudioFolder$'/*.wav
Sort
numberOfWavs = Get number of strings
if numberOfWords <> numberOfWavs
exit ("Mismatch: ", numberOfWords, " words vs ", numberOfWavs, " audio files.")
endif
for i from 1 to numberOfWavs
selectObject: "Strings wavList"
wavFile$ = Get string: i
selectObject: "Strings wordList"
word$ = Get string: i
fullWavPath$ = "'AudioFolder$'/'wavFile$'"
Read from file: fullWavPath$
soundName$ = selected$("Sound")
To TextGrid (silences): 75, 0, -35, 0.15, 0.1, "", word$
selectObject: "TextGrid " + soundName$
Set tier name: 1, "word"
tgFile$ = replace$(fullWavPath$, ".wav", ".TextGrid",1)
Save as text file: tgFile$
appendInfoLine: "Annotated: ", wavFile$, " with label: ", word$
endfor
select all
Remove
appendInfoLine: "Done! ", numberOfWavs, " TextGrids created."
5.2.2 The dictionary by linguists
We prepared a Bora pronunciation dictionary, bora_dict.txt, for the list of words collected by Jose.
Each word in this dictionary is transcribed in IPA, with individual IPA symbols separated by spaces and a tab character separating the word from its transcription.
<oov> oov
{LG} spn
{SL} sil
aabéváa aː p é b âː
aacu aː kʰ u
aamédítyuváa aː m é t í tʲʰ u b âː
aaméne aː m é n e
aaméváa aː m é b âː
aamɨ́nema aː m ɨ́ n e m a
aanévané aː n é b a n é
aanéváa aː n é b âː
aaúváa aː ú b âː
acháháchá a t͡sʲʰ á ʔ á t͡sʲʰ á
adówatu a t ó k͡p a tʰ u
adówááñé a t ó k͡p áː ɲ é
ahdújucóváa a ʔ t ú h u kʰ ó b âː
ajchóta a h t͡sʲʰ ó tʰ a
allúrí a t͡sʲ ú r í
...
Then we can clean up the project repository.
The bora_corpus/ repository contains both the sound files and their corresponding input transcriptions.
A tgs/ repository is added to house the output TextGrids.
.
├── bora
... ├── bora_dict.txt
├── wordlist.txt
├── create_input_tgs_from_wordlists.py
├── create_input_tgs_with_sils.praat
├── ...
├── tgs # for output TextGrids
└── bora_corpus
├── 01_sp_Panduro_BOR001_20250203_001.wav
├── 01_sp_Panduro_BOR001_20250203_001.TextGrid
├── 01_sp_Panduro_BOR001_20250203_002.wav
├── 01_sp_Panduro_BOR001_20250203_002.TextGrid
└── ...
5.3 Training acoustic models using MFA
Before we start, use the mfa validate command to look through the training corpus, bora_corpus/ in our case, and to make sure that the dataset is in the proper format for MFA.
mfa validate --clean --single_speaker bora_corpus bora_dict.txt --output_directory ~/Wip/bora
The output of this command reports on aspects of the training corpus including the number of speakers, the number of utterances, the total duration, the missing transcriptions or audio files if any, the Out of Vocabulary (oov) items if any, etc. You can see some of the INFO lines printed in the Unix Shell as follows:
INFO Corpus
INFO 913 sound files
INFO 913 text files
INFO 1 speakers
INFO 1773 utterances
INFO 5584.087 seconds total duration
INFO Sound file read errors
INFO There were no issues reading sound files.
INFO Feature generation
INFO There were no utterances missing features.
INFO Files without transcriptions
INFO There were no sound files missing transcriptions.
INFO Transcriptions without sound files
INFO There were no transcription files missing sound files.
INFO Dictionary
INFO Out of vocabulary words
INFO There were no missing words from the dictionary. If you plan on using the a model
trained on this dataset to align other datasets in the future, it is recommended that
there be at least some missing words.
...
The above output indicates that we passed our data validation. If there are any missing files or the number of speakers is incorrect, you will need to fix the problems and run mfa validate again. Oscillate between these two steps until you have validated your data.
The MFA command for training a new acoustic model is mfa train, which takes three arguments:
mfa train [OPTIONS] <corpus_directory> <dictionary_path> <output_model_path>
For more details, see the official guide.
I have added an optional argument --output_directory to put the output TextGrids for our training data.
mfa train --clean --single_speaker bora_corpus bora_dict.txt bora_model.zip --output_directory tgs --subset_word_count 1 --minimum_utterance_length 1
If you see the following few lines at the end of the Shell output, congratulations 🎉 on completing training an acoustic model.
INFO Finished exporting TextGrids to xxxxxx!
INFO Done! Everything took xxxxx seconds
An example of the TextGrid output is as follows:
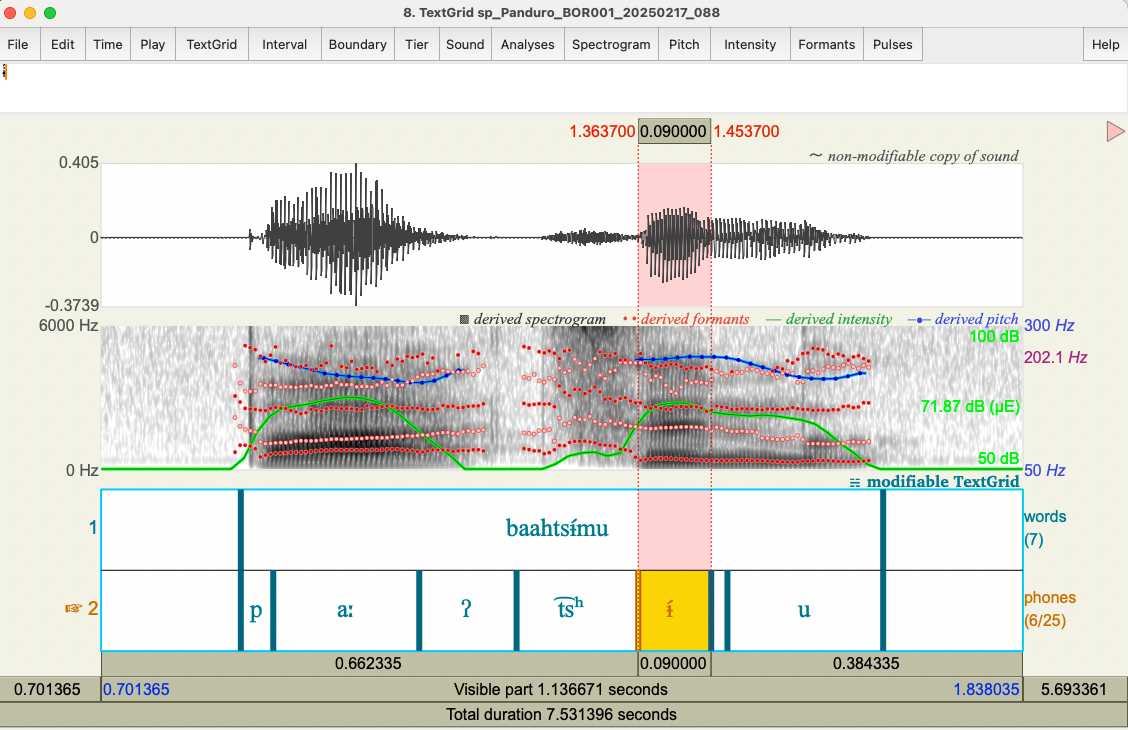
sp_Panduro_BOR001_20250217_088.wavWith such a small training corpus (~1.55 hours), the resulting alignment is surprisingly good. Although in the example above, the alignment for the bilabial nasal /m/ and vowel /u/ is off.
5.4 Next steps
The Bora DoReCo dataset may help us improve the mini acoustic model with more speech data from more speakers. (coming soon)