Exploring individual speaker performance within a forensic automatic speaker recognition system
 Poster presented at the UK and Ireland Speech Workshop (UKIS), Cambridge, UK. 1-2 July 2024.
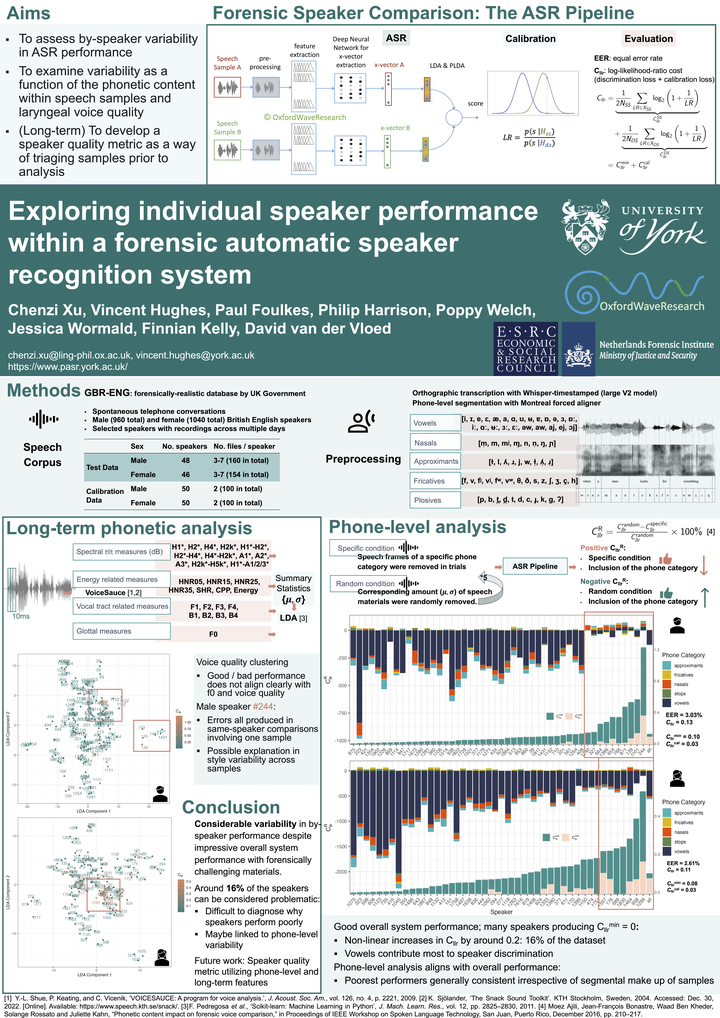
Poster presented at the UK and Ireland Speech Workshop (UKIS), Cambridge, UK. 1-2 July 2024.A key issue for automatic speaker recognition (ASR), particularly for forensics, is our lack of understanding about why certain voices prove more or less of a challenge for systems. In this paper, we focus on variability in individual speaker performance within an x-vector ASR system and examine this variability as a function of the phonetic content within speech samples. The inclusion of vowels generally improved performance, but not for all speakers. Indeed, some speakers produced broadly the same Cllr irrespective of the phonetic content in the speech samples. Poor ASR performance was not well correlated with long-term laryngeal features (f0 and laryngeal voice quality) and these features may provide additional speaker discriminatory information for some speakers. We discuss the implications of these findings in terms of developing a speaker quality metric for flagging potentially problematic speakers prior to ASR comparison.
Dr Chenzi Xu
Leverhulme Early Career Fellow
My research interests include speech prosody, speech perception, and speech technology.