Automatic speaker recognition with variation across vocal conditions: a controlled experiment with implications for forensics
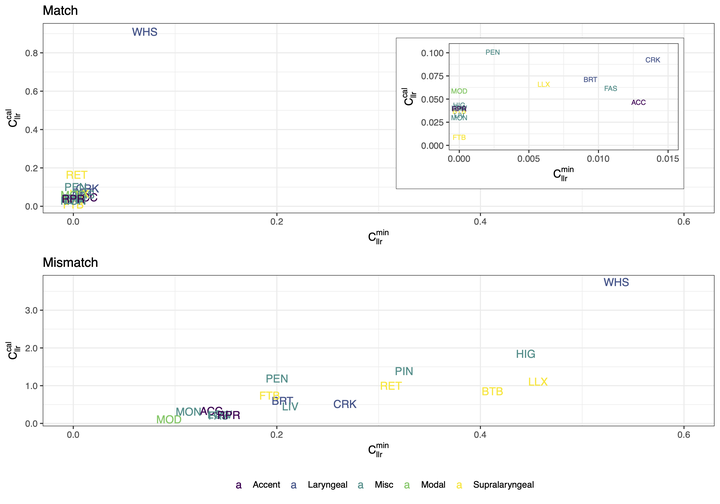 Cllr in matched and mismatched conditions.
Cllr in matched and mismatched conditions.Automatic Speaker Recognition (ASR) involves a complex range of processes to extract, model, and compare speaker-specific information from a pair of voice samples. Using heavily controlled recordings, this paper explores the impact of specific vocal conditions (i.e. vocal setting, disguise, accent guises) on ASR performance. When vocal conditions are matched, ASR performance is generally excellent (whisper is an exception). When conditions are mismatched, as in most forensic cases, we see an increase in discrimination and calibration error in some cases. The most problematic mismatches are those involving whisper and supralaryngeal vocal settings; these produce the greatest phonetic changes to speech. Mismatches involving high pitch also produce poor performance, although this appears to be driven by speaker-specific differences in articulatory implementation. We discuss the implications of the findings for the use of ASR in forensic casework and the interpretability of system output.
Dr Chenzi Xu
Assistant Professor
My research interests include speech prosody, speech perception, and speech technology.