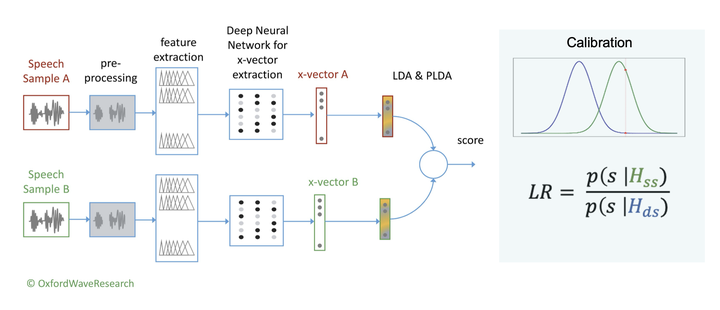
 A typical Automatic Speaker Recognition pipeline.
A typical Automatic Speaker Recognition pipeline.Automatic speaker recognition (ASR) systems usually take a pair of speech recordings as input, extract their speaker embeddings using deep learning (e.g. x-vectors; Snyder et al. 2018), and output through a classifier a speaker similarity score, which is in turn calibrated to a likelihood ratio. Despite the increasing accuracy of the ASR prediction, relatively little is known about the relationship between voice properties and ASR outputs. It has thus been a challenge to explain the output to an end-user in forensic context. This study aims to improve the interpretability of the scores by an ASR system by assessing how acoustic mismatches related to speech production impact different-speaker scores on a given evaluation corpus. Hautamäki and Kinnunen (2020) identified the most prominent factor in explaining low same-speaker scores as the difference in long-term f0 mean. This study focuses on the different-speaker scores in forensically realistic data and explores how differences in a range of acoustic features contribute to the discrimination of speakers. In particular, which acoustic similarities between speakers contribute to more difficult discrimination?
In this experiment, we model the impact of acoustic distance on the ASR score in discriminating speakers with similar demographic profiles. The study utilised a subset of the Home Office Contest corpus* containing 155 mobile phone recordings, all from different male speakers of London English. Each recording is a single channel of a mobile phone conversation, about 15 minutes long, with 8kHz sampling rate. Different-speaker (DS) comparisons were conducted using the pre-trained VOCALISE 2021 ASR system (version 3.0.0.1746; Kelly et al. 2019) with x-vectors and PLDA to generate scores. The scores were calibrated using a dataset of mobile phone recordings (8kHz, 16 bit, and single channel) from 20 speakers with a similar demographic profile – male London speakers – from the GBR-ENG corpus. We randomly selected two recordings per speaker for calibration. Bayesian calibration with Jeffreys non-informative priors was used due to the relatively small calibration set (Brümmer & Swart, 2014). The Cllr based on the DS likelihood-ratio values was 0.0152, 0.15% of the pairs (18/11925) had a positive calibrated score (i.e. lend contrary-to-fact support to a same-speaker decision). A range of acoustic features including f0, formants, formant bandwidths, jitter, shimmer, spectral tilts and so on were extracted automatically using Praat (Boersma & Weenink, 2022) and the OpenSMILE toolkit (Eyben et al. 2013). In our regression models, the dependent variable is the calibrated scores and the predictor is the acoustic distance between speakers in each comparison, represented by the absolute differences of the statistics of the selected long-term acoustic features or ensemble differences of feature groups. In general, the larger the acoustic distance the lower the calibrated score. Specific pairs that were difficult to discriminate in the ASR system are further examined and discussed. The findings will help us to flag or predict difficult voices for the ASR system to discriminate, and facilitate further exploration on how the discrimination may be improved with score calibration based on a dataset with acoustically similar speakers.
*Both GBR-ENG corpus and Home office Contest corpus belong to a telephonic speech database collected for the UK Government for evaluating speech technologies. Further details on application.
References
Brümmer, N., & Swart, A. (2014). Bayesian calibration for forensic evidence reporting. arXiv preprint arXiv:1403.5997.
Eyben, Florian, Felix Weninger, Florian Gross, and Björn Schuller. 2013. “Recent Developments in openSMILE, the Munich Open-Source Multimedia Feature Extractor.” In Proceedings of the 21st ACM International Conference on Multimedia. New York, NY, USA: ACM. https://doi.org/10.1145/2502081.2502224.
Hautamäki, Rosa González, and Tomi Kinnunen. 2020. “Why Did the X-Vector System Miss a Target Speaker? Impact of Acoustic Mismatch upon Target Score on VoxCeleb Data.” In Interspeech 2020. ISCA: ISCA. https://doi.org/10.21437/interspeech.2020-2715.
Kelly, F., Forth, O., Kent, S., Gerlach, L. and Alexander, A. (2019) Deep neural network based forensic automatic speaker recognition in VOCALISE using x-vectors. Proceedings of the Audio Engineering Conference: 2019 AES International Conference on Audio Forensics.
Boersma, P. & Weenink, D. (2022) Praat: doing phonetics by computer [Computer program]. Version 6.2.06, retrieved 23 January 2022 from https://www.praat.org.
Snyder, D., Garcia-Romero, D., Sell, G., Povey, D. and Khudanpur, S. (2018) X-vectors: robust DNN embeddings for speaker recognition. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, 5329–5333.
Dr Chenzi Xu
Assistant Professor
My research interests include speech prosody, speech perception, and speech technology.