Post-alignment Options
5.1 Check the Alignment Results
When you have obtained the automatically time-aligned .Textgrid files using P2FA or MFA, it is always good to check them together with the corresponding .wav files. You can take a sample and open them in Praat, and listen to the aligned intervals to see if the alignment results are good. My corpus isn’t very big, so I checked every single file before further analysis. Occasionally you’ll find some alignment errors, you can manully correct them but do keep a log of the changes!
5.2 A Comparison between P2FA and MFA
Having visually examined their output of some of my Mandarin data, I think P2FA tends to be a better aligner than MFA with the pre-trained models. MFA can be improved by further training with a larger corpus I guess. The following image shows the alignment output of a phrase from P2FA and MFA.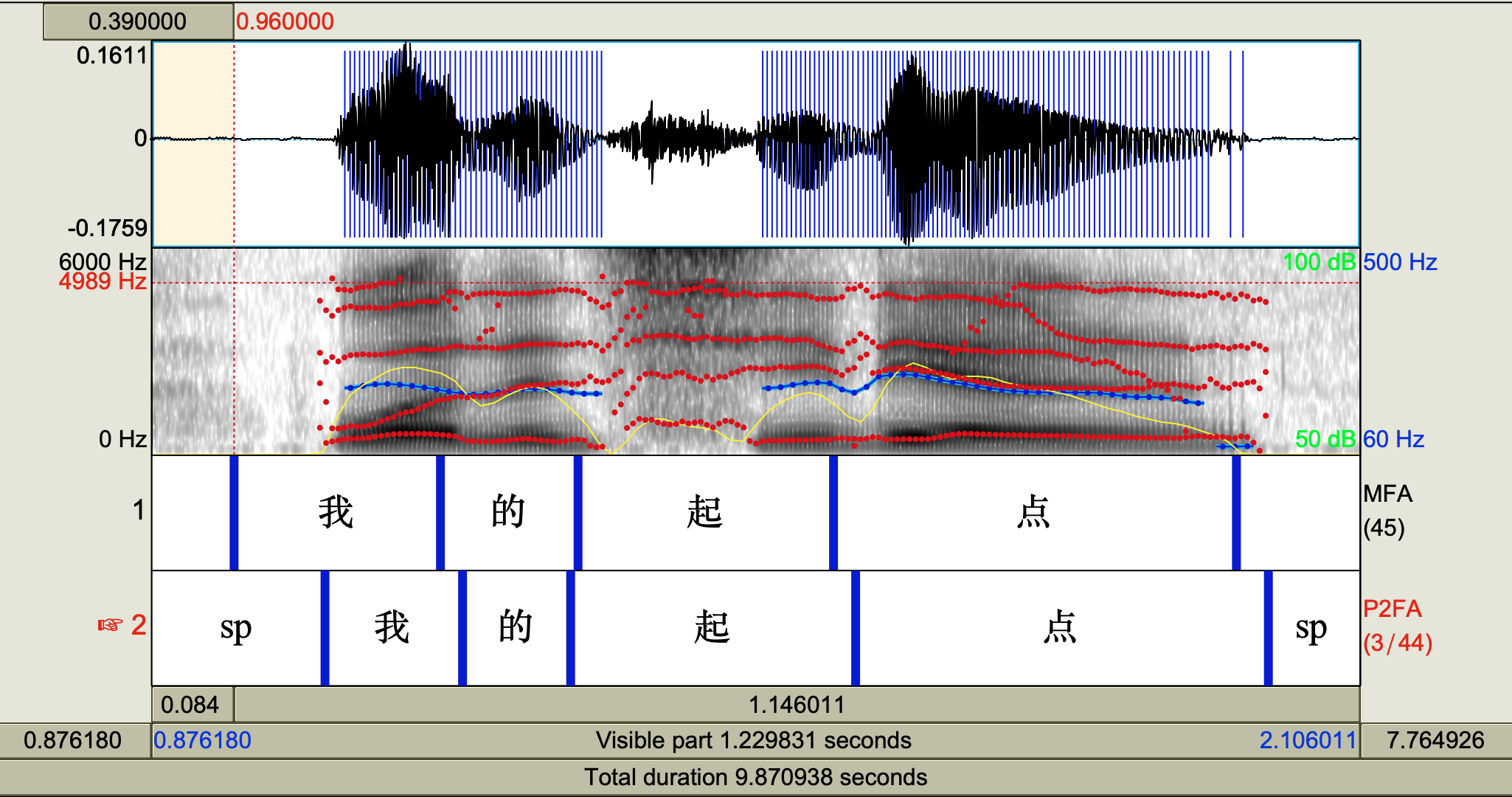
5.3 Converting Textgrids to Tables
When you have a finalised set of .Textgrid files, you might want to extract the temporal information from the alignment. .Textgrid format, especially the long form, isn’t very reader-friendly. So I wrote a few Python snippets to convert the .Textgrid (both the long and short forms) to .txt or .csv with information presented in a more readable table format. They are available at my Github
repository. The README.md will take you from there.
The following example demonstrates the convertion.
- An example of the long form
.TextGridfile:
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0.0
xmax = 9.8709375
tiers? <exists>
size = 2
item []:
item [1]:
class = "IntervalTier"
name = "words"
xmin = 0.0
xmax = 9.8709375
intervals: size = 45
intervals [1]:
xmin = 0.0000
xmax = 0.1900
text = "然"
intervals [2]:
xmin = 0.1900
xmax = 0.5700
text = "后"
- An example of the short form
.TextGridfile:
File type = "ooTextFile short"
"TextGrid"
0.0125
9.862499999999999
<exists>
2
"IntervalTier"
"word"
0.0125
9.862499999999999
44
0.0125
0.0625
"sp"
0.0625
0.2025
"然"
0.2025
0.6124999999999999
"后"
The desired output table format:
然 0.0000 0.1900 0.1900 c01_101
后 0.1900 0.5700 0.3800 c01_101
In the output table, the first column is the orthographic transcripts, followed by the starting times (s), ending times (s), duration (s), and filenames (without extensions). It can be written into a .txt or .csv file.